很多人刚开始写 Telegram Bot 时,只知道通过 getUpdates 拉取消息,但很快就会发现问题:服务器跑着跑着,消息堆积成山,要么处理重复,要么因为网络波动丢了一大截。想要让你的 Bot 运行稳定,甚至能处理几百个群的消息,你需要掌握一套更硬核的处理链路。
让消息获取更高效:从轮询到 Webhook
如果你还在用 getUpdates 循环请求,赶紧换掉吧。轮询不仅会造成不必要的 API 调用,还会带来几秒钟的延迟。对于追求实时性的 Bot,Webhook 是唯一选择。
当你配置好 Webhook 后,Telegram 服务器会在有新消息时,主动把数据推送到你的服务器。踩坑点:记得一定要校验 update_id。虽然 Telegram 尽量保证顺序,但在网络极端情况下,还是可能收到乱序或重发的数据。我通常会在数据库里存一个 last_update_id,如果新进来的 ID 小于等于这个值,直接丢弃,省得做无用功。
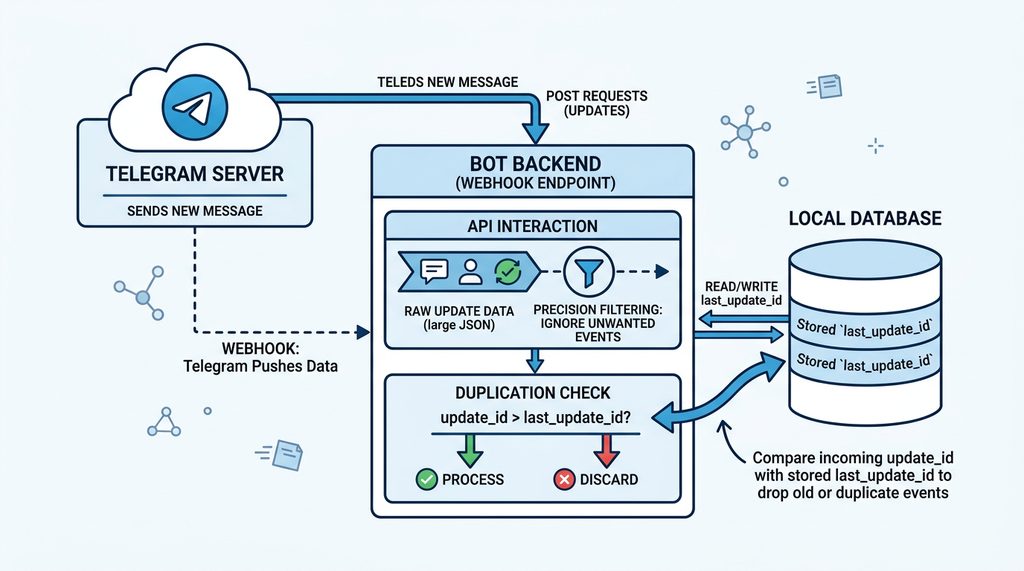
精准过滤事件:别被冗余数据淹没
Telegram 的 API 返回的 JSON 包非常大,包含了用户信息、聊天室背景、甚至是你不需要的各种状态更新。如果你每个字段都去解析,代码维护起来会像噩梦一样。
我的做法是建立一个“事件过滤器”。在进入业务逻辑前,先用一段代码对 update 类型进行拆分。比如只关注 message 且 text 字段不为空的,直接忽略 channel_post 或 edited_message(除非你的业务需要)。
- 使用
message.from.is_bot进行第一轮筛选,直接过滤掉其他机器人的互动,防止陷入无限递归回复。 - 利用
chat.type判断是私聊还是群组,群组里只抓取包含@你的机器人名字的消息,能帮你过滤掉 90% 的无关闲聊。
消息去重:应对重发机制的保命符
Telegram 的服务器有时候很“执着”,如果它没收到你返回的 200 OK 状态码,它会认为消息没投递成功,然后不断重发。这就是为什么你的 Bot 经常会出现“连发三条回复”的原因。
要解决这个问题,你需要一个简单的内存缓存(比如 Redis)。每处理一条消息,就把它的 message_id 存进去,设置 10 分钟的过期时间:
if (cache.exists(message_id)) {
return; // 已经处理过了,跳过
}
// 业务逻辑处理...
cache.set(message_id, true, 600);
这个小技巧能让你在网络抖动时,依然保持程序的逻辑一致性,不至于因为重复触发而给用户发一堆乱码。
自动化 Telegram Bot 的关键不在于功能有多复杂,而在于对底层 API 数据的把控能力。从切断轮询、精准过滤非必要事件,再到用 ID 缓存来防重,这三步走完,你的机器人就能从“玩具”变成真正能干活的工具了。别纠结于复杂的框架,先把这套稳健的消息流跑通,后续扩展功能会轻松得多。